In the previous article: Understanding Gray Area Failure, we learned about what a Gray Area is, how does it come into existence, its consequent failures, and how we could potentially prevent such failures. But in reality, it is still a gray area and such unidentified or unattended gray areas could lead to failures that impact in such a way that we cannot recover in-place and have to fail over to another Availability Zone or Region, in order to maintain the availability of the services offered to our clients. Following are the empirically devised strategies to recover from a disaster.
Disaster Recovery Strategies
All the strategies involve a non-zero RPO due to the loss of data in replication asynchronously. Therefore, ensuring that the disaster recovery is not triggered based off of a false positive event of impact is vital.
Active/Passive paths are more cost effective.
Following are the 2 most important factors to consider while choosing a DR strategy.
RPO – Recovery Point Objective – The amount of tolerance to data loss the system can allow between the recovery point and the last good state.
RTO – Recovery Time Objective – The amount of time between, unavailability of the system and the restoration point. Tolerance toward downtime of the service.
The recovery strategies can be broadly classified into 2 groups:
- Active/Passive – where there is a failover from one resource group to another; while only one of them are completely active and are taking the workload to process. Hence the name, active/passive.
- Active/Active – where there is no failover per say. Both the resource groups (regions/clusters/availability zones) take the workload on to process.
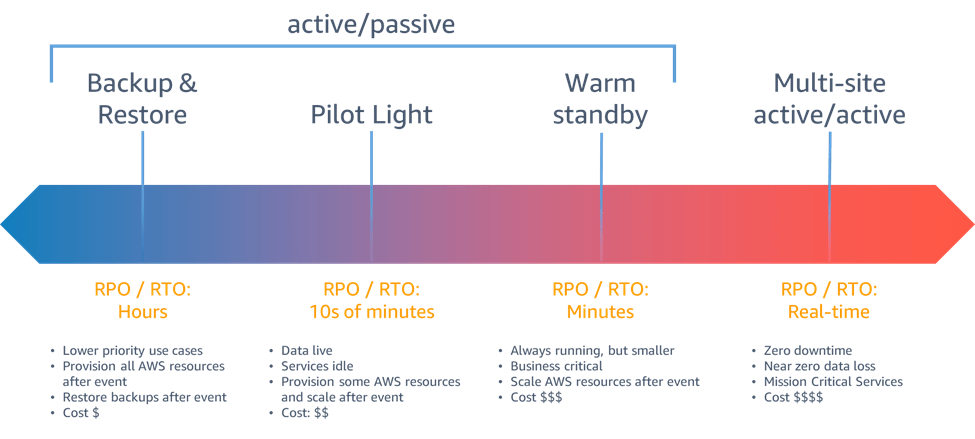
Following are the active/passive disaster recovery strategies in an increasing order of cost and decreasing order of performance factors such as RTO and RPO.
- Backup & Restore – Most cost effective solution. But is time consuming. Longer down times and poorer RTOs. Alongside of backing the data up to prevent any data loss, the infrastructure, configurations, and app code need to be deployed on the recovery region, which is time consuming. And has to be done to result in a same setup as that of the original Region. Hence, Infrastructure as a Code is the best way to get a repeatable infrastructure.
S3 object versioning with a continuous backup would help protect against data loss due to corruption or destruction, giving the shortest time to back the data up === low RTO
Also the object versioning protects against unintentional data loss due to threats or malicious modifications or inadvertent deletions.
RPO/RTO : HOURS - Pilot Light – Involves replication of data from one region to the other and provisioning a copy of core workload infrastructure.
– Data replication resources such as databases, object storage are always on. While the app servers are loaded with app code but are idled/switched off and are only used during testing or when disaster recovery failover is invoked. Always ready to switch things on and provision a full scale production environment.
– Infrastructure, configurations, app code and the data are all readily available unlike the backup & restore approach where the re/deployment is time consuming to be brought back up in the same order (especially with large sets of microservices)
Here the main time consumption is in bringing the app servers back up.
RPO/RTO – 10(s) of minutes. - Warm Standby – this approach ensures that there is a scaled down, but a fully functional copy of your production environment in another region. Infrastructure, configuration and app code are all deployed but are scaled down to take a limited workload on, but are readily scalable and only take minutes to scale out as the scaling is horizontal.
AWS Accelerator, CloudFront etc., can be used to control the request routes through network layer so that the requests do not go to the affected region. Best if it is a fully managed service which is in the region affected so that AWS’ aforementioned reliable services can be used for a Disaster recovery.
RPO/RTO: minutes
- Multi-site active/active (most expensive) – Both the regions take requests/load.
There is no failover in this scenario as both the regions take the workload.
Therefore, for active/active strategy, there would be policies that determine which user request goes to which region.
RPO/RTO: real time
For reads – it is usually recommended to go with “read-local” approach.
For writes – there are a few possible strategies to choose from
– write-global: all the writes go to a single region. If this region fails, another regions starts accepting writes. Aurora global database is a good fit as it supports synchronization with read-replicas across regions, while the write is directed to one global aurora table. This table further syncs with the read-replicas across regions. And, any of these read-replicas can be promoted to take read/write responsibilities in under a minute. Aurora also supports write forwarding. This allows forwarding of write calls or SQL statements in a secondary cluster to perform it on a primary cluster.
– write-local: writes to the closest region. Amazon DynamoDB global table enables such a strategy, allowing read and writes from every region that the table is deployed on. Thus one local write is sufficient, to enable multi region global reads and writes. It uses “last writer wins” reconciliation strategy to resolve concurrent updates.
– write-partitioned: Best suited for scenarios where concurrent writes are expected at a high frequency. Writes are assigned to a specific region based on the partition key (such as user ID) to avoid write conflicts. Amazon s3 replication configured bi-directionally, can be used for this case Currently it supports replication between 2 regions. It is important to enable replication modification sync (in order to also replicate the metadata of the replicated data such as ACLs, object tags, object locks on replicated objects) In addition to replication, the strategy must also include point-in-time backups to protect against data corruption and destruction events.
The diagram below illustrates all the four DR strategies aforementioned.
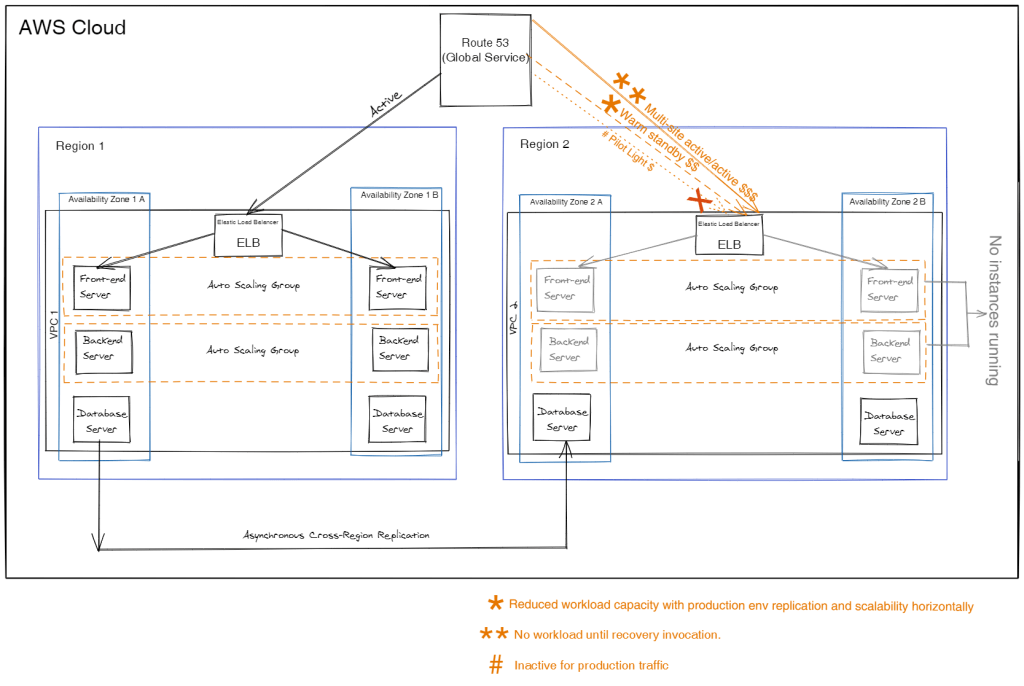
As we learn the different strategies that can suit our use case for a disaster recovery, we also realize the importance of the choices we make in picking the tools that sit on either a control place or a data plane, defining its resiliency in performing a disaster recovery execution. Therefore, let’s take a look at what these planes are and how they influence our strategies.
What is AWS control plane and data plane?
Within AWS, a common pattern is to split the system into services that are responsible for executing customer requests (the data plane), and services that are responsible for managing and vending customer configuration (the control plane).
AWS separates most services into the concepts of control plane and data plane. These terms come from the world of networking, specifically routers. The router is a data plane, whose main functionality, is moving packets around based on rules. But the routing policies have to be created and distributed from somewhere, and that’s where the control plane comes in.
Control planes provide the administrative APIs used to create, read/describe, update, delete, and list (CRUDL) resources. For example, the following are all control plane actions: launching a new Amazon Elastic Compute Cloud (Amazon EC2) instance, creating an Amazon Simple Storage Service (Amazon S3) bucket, and describing an Amazon Simple Queue Service (Amazon SQS) queue. When you launch an EC2 instance, the control plane has to perform multiple tasks like finding a physical host with capacity, allocating the network interface(s), preparing an Amazon Elastic Block Store (Amazon EBS) volume, generating IAM credentials, adding the Security Group rules, and more. Control planes tend to be more complicated orchestration and aggregation systems relative to data planes.
The data plane is what provides the primary function of the service. For example, the following are all parts of the data plane for each of the services involved: the running EC2 instance itself, reading and writing to an EBS volume, getting and putting objects in an S3 bucket, and Route 53 answering DNS queries and performing health checks.
Data planes are intentionally less complicated, with fewer moving parts compared to control planes, which usually implement a complex system of workflows, business logic, and databases. This makes failure events statistically less likely to occur in the data plane versus the control plane. While both the data and control plane contribute to the overall operation and success of the service, AWS considers them to be distinct components. This separation has both performance and availability benefits.
This knowledge becomes essential while making decisions around choosing the tools to use. When implementing recovery or mitigation responses to potentially resiliency-impacting events, using control plane operations can lower the overall resiliency of your architecture. For example, you can rely on the Amazon Route 53 data plane to reliably route DNS queries based on health checks, but updating Route 53 routing policies uses the control plane, so do not rely on it for recovery.
Regional Failover using Route 53
As the impact grows from apps to AZs, to clusters to the region level, Route 53 becomes the option as the other services are limited to a region and cannot directly see outside of the region they are deployed in; and would necessitate gateways. Whereas, Route 53 is a service that sits above regions and becomes a possible solution path. Route 53 can be used in 2 ways to handle a disaster recovery. Automatic and Manual.
Automatically using Route 53 based on health checks and can be prone to errors and inevitable time and data losses in case of a false positive of a disaster event. Not recommended.
The next approach is a manual one using a newly introduced service by AWS called Amazon Route 53 Application Recovery Controller or Amazon Route 53 ARC. Manual approach is recommended. Using Amazon Route 53 ARC, we can create health checks that do not actually run health checks and rather act as on/off switches to the recovery endpoint and away from the failed or troubled primary endpoint registered under the same Route 53 domain name.
This is a data plane API and is more resilient and less prone to resiliency failures.
Another manually initiated failover is by using weighted routing policies, and change the weight of the primary and recovery regions so that all traffic goes to the recovery region. However, this is a CONTROL PLANE OPERATION (managing and vending customer configurations) and therefore not as resilient as the data plane (executing customer requests) approach.
Conclusion: In essence, it is a combination of the aforementioned strategies that work the best, rather than trying to force fit our system into one of them.
Thank you, for the read. Appreciate your time and also request you to share your knowledge with people around so we can build a strong knowledgeable and literate community that can be devoid of unawareness and ignorance. Please feel free to leave your comments.
